手写WEB服务器-03-相关代码
1.基础通信部分
前文说到,web服务器本质上是一个tcp服务器,因此跟tcp服务器相关的所有逻辑都需要实现。
1.1 忽略SIGPIPE信号
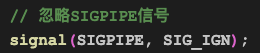
这是最常见的容易被忽略的一个逻辑,当客户端连接断开,而服务器还尝试往客户端套接字上写数据时(这个场景实际运行时经常遇到),就会触发SIGPIPE信号,触发这个信号的默认行为是退出进程,因此服务器必须要捕捉并忽略这个信号,否则你的服务器就会在实际运行时莫名其妙的退出,没有任何错误日志和内存转储文件等,让人十分头疼。
1.2 打开侦听端口
首先你应该调用socket函数建立一个侦听套接字:

然后填上服务器的侦听地址:
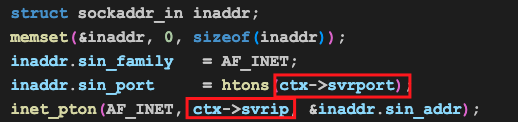
在我们的服务器中,这两个也是个配置:
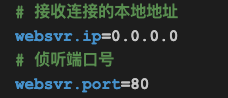
其中80是侦听端口,这个我们之前已经提过,不再解释。
0.0.0.0表示,服务器可接收来自所有本地地址(可以简单理解为网卡地址)的连接。
在web服务器实际所部署的服务器主机上,一般都有多个网卡,假设对外的网卡地址是192.168.1.1,对内的网卡地址是192.168.2.1,我们可以把侦听地址配置为192.168.2.1,这样该web服务器就只能通过192.168.2.1访问,不能通过192.168.1.1访问了(注意这个是操作系统层面实现的逻辑,不是我们的web服务器实现的逻辑)。
然后就是常见的bind、listen,bind用于绑定上面提到的本地地址(包括网卡ip和端口),listen用于告诉操作系统,我准备好接受来自上述地址的链接了。


我们准备用epoll实现多路复用机制,因此要调用相关接口将其加到epoll的事件侦听列表中:
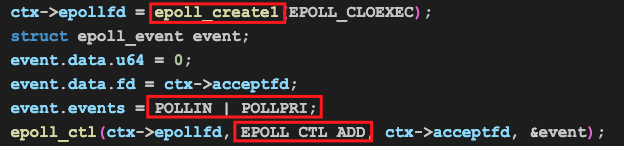
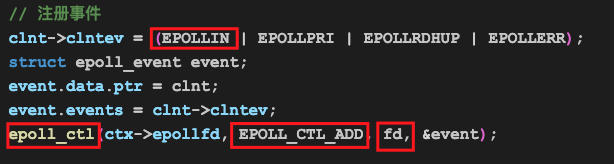
上述代码表达的含义是:告诉(EPOLL_CTL_ADD)epoll,我关注侦听套接字(acceptfd)的可读事件(POLLIN | POLLPRI),如果上述事件发生的话,通知我去处理(即有客户端连接到我所侦听的地址和端口时,通知我去处理)。
1.3 事件轮询
先看代码:
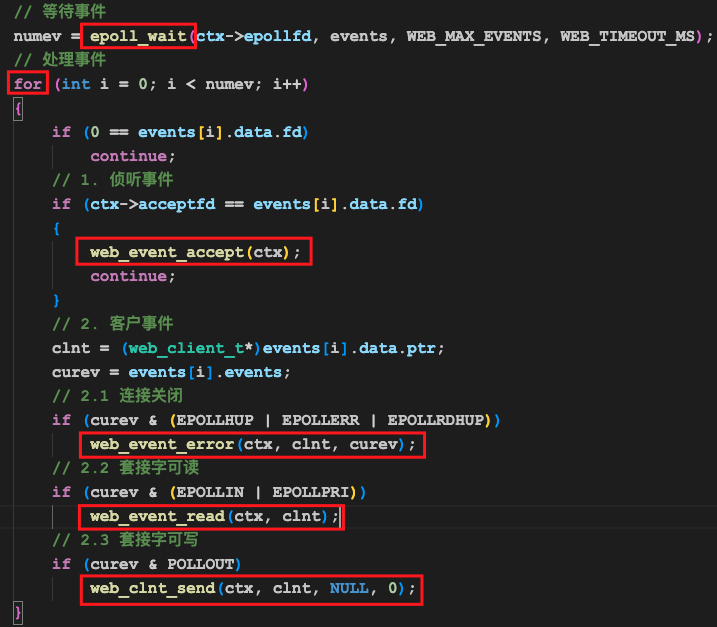
上述代码是web服务器的主流程,是我们的web服务器中最重要的一段代码。
第一个要点是epoll_wait,这是操作系统提供的epoll机制的其中一个系统函数。
前面我们提到,epoll是一种多路复用的机制。
什么是多路复用呢?简单理解就是,在一个进程/线程中处理多个套接字连接的一种机制。
我们的web服务器是一个单进程(单线程)的tcp服务器程序,tcp服务器的一个刚需就是同时(或者看似同时)处理多个客户端连接的请求(这就是所谓的高并发),多个客户端连接在服务器程序看来就是多个套接字,这些套接字对应的连接上可能同时都有数据要收取或者发送(比如100个浏览器同时向你发送GET请求),你怎么用一个进程同时处理这100个套接字呢?
最简单的思路是,我们可以写个for循环一个一个地去检测套接字上是否有数据需要收取,这样当然可以,但是效率不高,因为服务器需要不停地轮询,跑在一种类似死循环的状态,比较浪费CPU资源。
好在操作系统直接提供了这种轮询机制,你可以把需要检测的套接字列表告诉操作系统(epoll_ctl,EPOLL_CTL_ADD),然后调用操作系统的轮询函数(epoll_wait),让操作系统帮你去检测各个套接字上是否有事件发生(比如有数据需要收取)。当调用这个函数的时候,你的程序会阻塞在轮询函数(epoll_wait)上,等待该函数返回。当轮询函数返回后,他会给你一个参数,告诉你有几个套接字上事件发生(比如),然后你挨个遍历处理就行了。
值得一提的是,操作系统提供的轮询接口经历过几次更新,最古老的是select和poll,这个是从UNIX时代就继承过来的,后来LINUX平台增加了epoll接口,相比select和poll更高效,更公平,所以我们的程序中直接使用epoll来实现。
知道原理后,再回头看代码:

这行代码中,events是一个结构体数组(结构体类型为struct epoll_event),它是epoll_wait的一个输出参数,里面存放的是需要我们处理的事件信息,这些信息包括套接字文件描述符以及事件类型等。numev是epoll_wait函数的返回值,他表示有几个事件需要我们处理,假设这个值是10,这表示有10个事件需要我们处理,我们遍历events数组的前10个元素查看相关信息并处理即可。
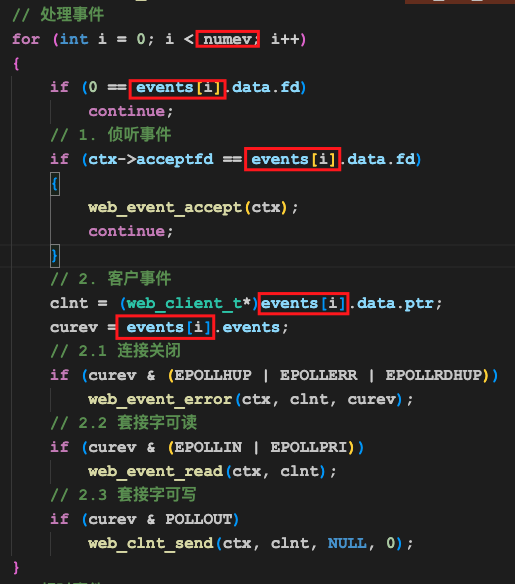
注意到,我们分别用到了events的三个元素:
- data.fd:用于存放套接字的文件描述符,即哪个连接发生了需要处理的事件
- data.ptr:用于存放一些自定义的信息,以指针的形式存在,在EPOLL_CTL_ADD的时候自己填写,当ADD的套接字上有事件发生时,操作系统会把这个指针原样返回给你,方便你使用
- events:指示发生了哪些需要处理的事件
在上述代码中,我们共处理了2类共4个事件:
- 侦听事件:当有客户端连接到服务器的时候触发
- 客户事件:
- 连接关闭事件:包括主动关闭和被动关闭,当客户端连接断开时触发
- 套接字可读事件:表明客户端连接给你发了一些数据,你需要收取并处理
- 套接字可写事件:表明客户端连接有数据接收能力,你可以给他发应答了
1.4 实际例子
下面我们用一个实际的例子来把整个代码流程串起来。
当我们执行(./websvr -d)启动web服务器的时候,websvr进程会执行到打开侦听端口这个过程:
建立侦听套接字:

填写服务器地址:

绑定端口、开始侦听:


然后我们调用epoll_ctl(EPOLL_CTL_ADD)把刚才建立的侦听套接字加到epoll的轮询列表中,开始轮询侦听套接字的事件:
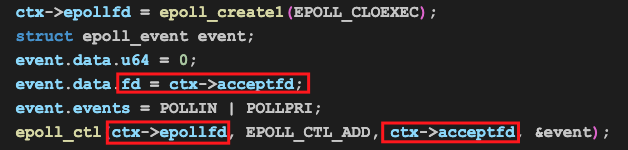
然后websvr程序就会进入到事件轮询的过程中:
其中web_loop函数内部就是在执行上面我们提到的epoll_wait等过程:
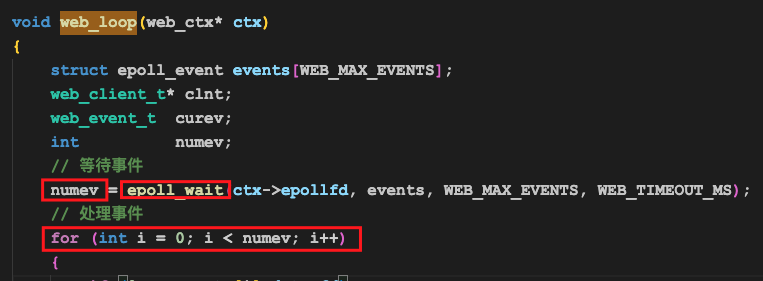
当没有客户端(浏览器)发起连接时,epoll_wait就会一直返回0,下面处理事件的循环就无法进入,相当于web_loop函数一直在空转。
当我们在浏览器输入地址发起连接时:
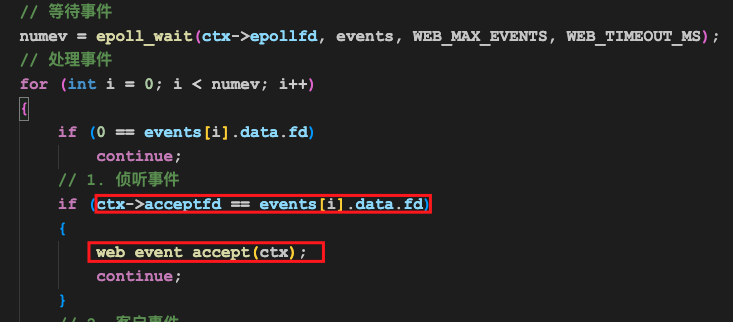
这里的epoll_wait函数就会返回1,然后我们遍历events数组的第一个元素,就会发现data.fd正好是我们在前面EPOLL_CTL_ADD的时候添加进去的那个侦听套接字的fd,然后我们就进入到了下面的web_event_accept执行过程中。
在这个过程中,我们调用accept4系统函数接收客户端浏览器的连接,这个函数返回一个fd(套接字文件描述符),这个fd就对应了我们前面发起的那个客户端浏览器的TCP链接,我们从这个fd上收数据,就是从客户端浏览器上收数据,我们朝这个fd上发数据,就是向客户端浏览器上发数据。
我们仍然调用epoll_ctl(EPOLL_CTL_ADD),把这个fd加到epoll关注的套接字列表中,让epoll帮我们轮询这个fd上的事件,包括客户端浏览器是否向我们发送了数据等事件。
然后我们又进到了web_loop这个函数中:
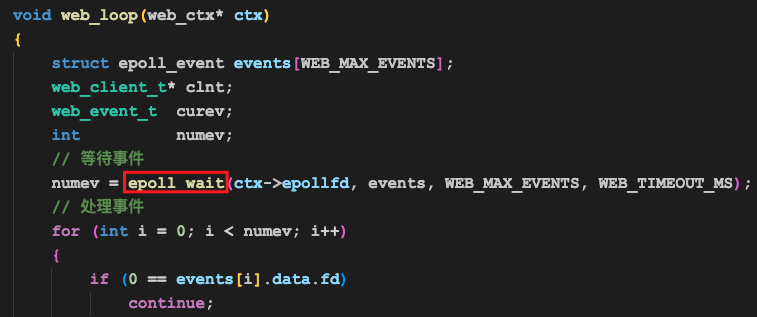
不同的是,之前epoll_wait只关注一个套接字的事件,即侦听套接字的事件,现在epoll_wait会关注两个套接字的事件,包括侦听套接字和刚才我们通过客户端浏览器发起的TCP连接的套接字。
在前一篇文章中我们提到,我们在浏览器输入地址并回车后,浏览器在发起TCP连接后会自动发送以下数据:
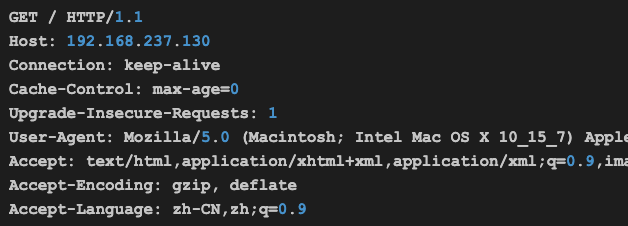
当上述数据到达服务器网卡,被操作系统感知后,操作系统会唤醒上述epoll_wait函数,然后我们的epoll_wait函数就会返回1:
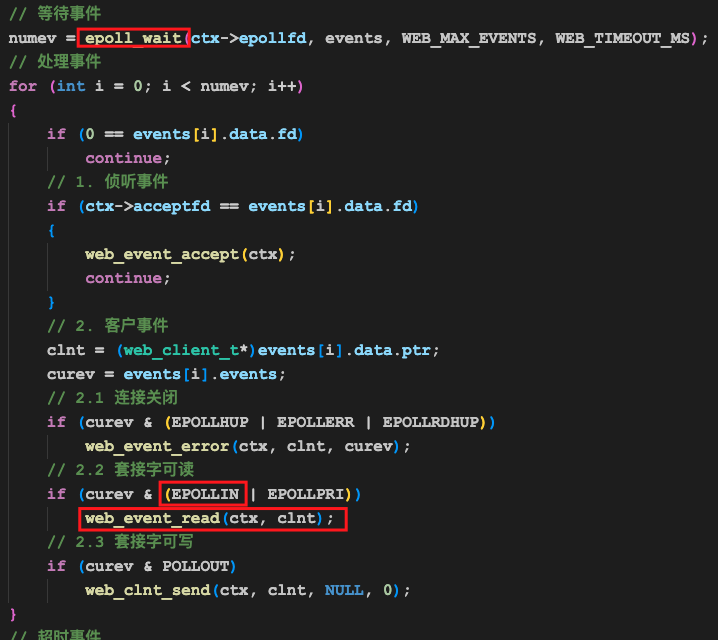
我们会检测到客户端浏览器的fd上EPOLLIN事件触发,然后我们就进入到web_event_read函数中了。
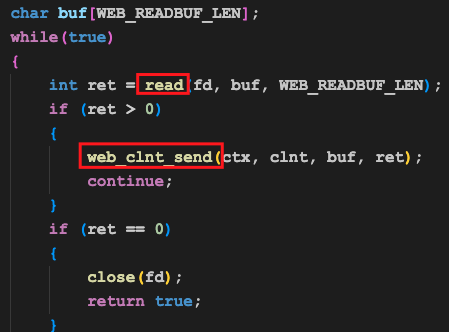
这个函数最核心的代码在下面:
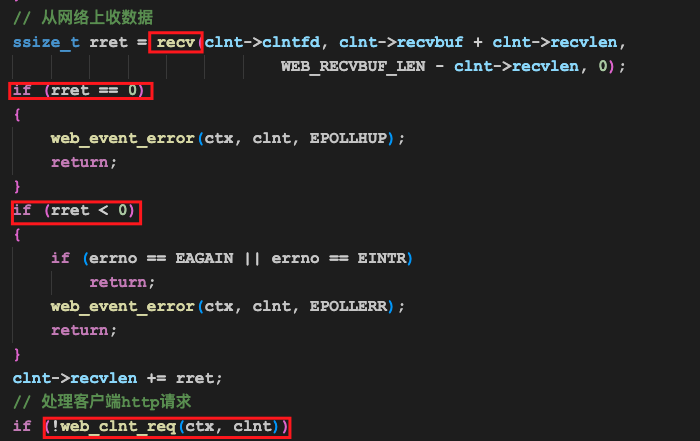
我们调用操作系统提供的recv函数,就能把客户端浏览器发送的那一堆字符串收下并保存到recvbuf变量中,以备后续解析使用。
recv的返回值有三种可能:
- 等于0,表示对端主动关闭了连接,即浏览器主动关闭了连接
- 小于0,一般表示连接异常断开了,当然也有例外,这不在我们的讨论范围内(感兴趣的可以查下非阻塞套接字)
- 大于0,才是真正收到了数据,此时的返回值表示收到了多少字节的数据
收据收完后(即前面那一堆字符串收完后),服务器就能处理了,包括字符串的解析,应答文件的打开和发送等,这个属于业务部分,我们后面再叙。
发送应答时,最终会调用到web_clnt_send这个函数,这个函数有两段核心逻辑,第一段是第一次调用的时候,我们拿到了一个字节数组,这代表了我们要发送的数据(即上一篇文章中那个index.html中的内容),我们把这个字节数组中的数据先保存到缓存中,先不发送。
然后为客户端浏览器的套接字注册一个可写信号,让epoll_wait过程驱动进行发送发送。

注册可写信号的过程如下:
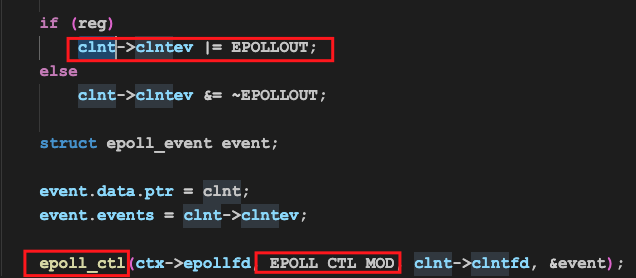
可以看到,我们调用的还是epoll_ctl函数,只不过这次我们注册的信号是EPOLLOUT,而非EPOLLIN。
这时候,程序又进到了epoll_wait那个函数中了:
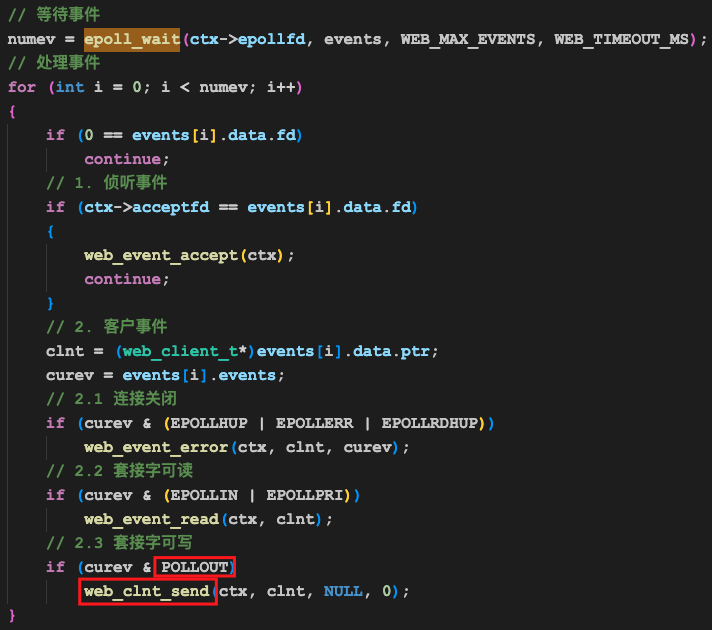
只不过这次触发的不是EPOLLIN,而是EPOLLOUT了。
然后我们又进入到了web_clnt_send这个函数中了,这时候才会运行它真正的发送逻辑:
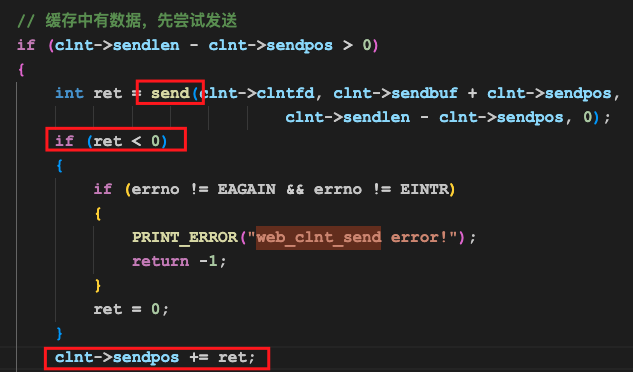
与recv不同的是,send的返回值只有两种可能,一种是小于0,一般表示连接断开了,一种是大于0,表示真正发送了一些数据(但是不一定一次发完,一次没发完后续再尝试接续发送即可)。
send函数发完后,数据就跑到了网络上,通过服务器的网卡发出去,再被客户端浏览器的网卡收走,最终被浏览器软件处理并展现。
2.http协议部分
2.1 主要流程
在前面的代码分析中,我们提到,web服务器收到那一堆http请求字符串后,调用了web_clnt_req进行处理。
这个函数的主要过程如下:
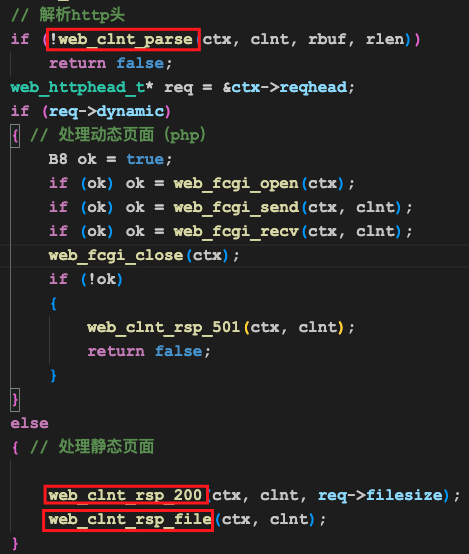
首先是从那一堆字符串中解析出相关信息,其中最主要的是要发送的文件路径。
然后是打开要发送的文件,把文件中的内容发送给客户端浏览器。
2.2 http头解析
首先是第一行的三个信息:
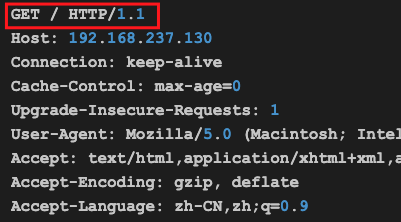
直接使用下面的代码读出:

结果如下:

然后解析uri,拼接出来一个完整的路径名:
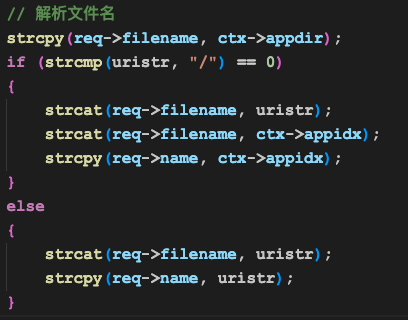
首先第一行的strcpy,会把”/”处理成”/root/www”。
然后下面的代码会判断客户端浏览器是否提供了具体文件名,比如”index.html”,如果没有,服务器就会根据配置为它加上一个文件名,即把”/root/www”变成”/root/www/index.html”。最终文件名被保存在了req->filename变量中。
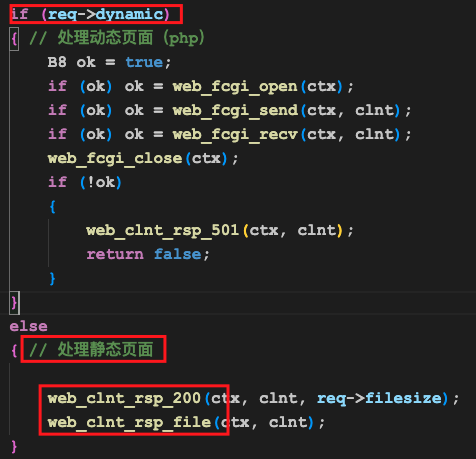
然后调用下面的代码,判断一下客户端请求的是动态页面还是静态页面:

以php结尾的我们称为动态页面(因为需要动态生成网页内容),否则我们称为静态页面。
然后我们就会进入到下面处理静态页面的分支中去:
2.3 http应答发送
处理静态页面包括两个主要过程。
第一个过程是http应答头发送,在我们的例子中,文件请求没啥问题,因此我们返回200错误码,表示http请求成功(而如果请求的文件不存在,我们需要返回404错误)。
http应答头长这样:
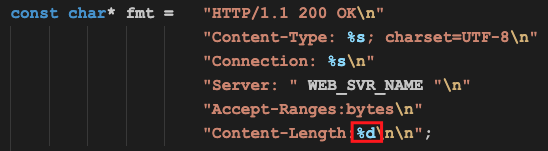
其中最主要的信息是Content-Length,表示我们接下来要发送多少字节的信息给客户端浏览器,在我们的例子中,就是下面这些信息的长度:
<!DOCTYPE html>
<body>Hello World!</body>
</html>第二个过程就是客户端浏览器所请求的具体文件的发送了:
首先是打开这个文件:

然后我们一边从文件read,一边调用我们前面封装好的接口给客户端发送数据即可: