使用lambda表达式替换宏定义代码段
1.什么是宏定义代码段
C/C++宏定义属于预处理阶段的功能,操作的对象是源代码。在预处理阶段,编译器根据用户定义的预处理指令,将源代码改造成另外一种形式。
需要特别注意的是,预处理指令虽然跟C/C++代码放在一个源文件里,但并不属于C++的一部分,因此不受C++语法规则的约束。而这一点,正是我们使用宏定义代码段的最重要的原因。
下面的代码展示了一个宏定义代码段的例子。
//compile with : g++ lambda_test_1.cpp -E -o lambda_test_1_after.cpp
#include <stdio.h>
#define BEFORE_ADD() \
int a, b, c; \
a = 1; \
b = 2
#define AFTER_ADD() \
printf("a + b = %d\n", c)
int main()
{
BEFORE_ADD();
c = a + b;
AFTER_ADD();
return 0;
}代码简单易懂,不再解释。
我们使用-E命令编译上述代码,命令如下:
g++ lambda_test_1.cpp -E -o lambda_test_1_after.cpp查看编译后的代码,发现main函数被替换成了如下的代码:

宏定义中的代码被简单粗暴地替换到了源文件中。
2.宏定义代码段的坏处
宏定义最大的问题是,你看到的代码和编译器看到的代码是不同的,这中间有一个预处理器翻译的环节,再加上宏定义的作用域是全局的,有时候翻译的结果可能并不如你所想,因此代码编译或运行起来可能会有一些奇奇怪怪的错误,很难排查。
a) 举个例子
看下面的代码:
//compile with : g++ -o lambda_test_2 lambda_test_2.cpp
#include <stdio.h>
#define X 2
#define Y 3+4
int main()
{
printf("X * Y = %d\n", X * Y);
return 0;
}你觉得运行结果是什么?
答案是10而不是24:

看下预处理器翻译的代码你就了然了:
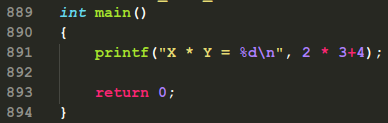
预处理器并没有计算3+4的结果与2相乘,而是直接把X、Y代表的文本进行了替换!这样的话,由于乘法的优先级比较高,2和3会先乘,然后再和4相加!
b) 再举个复杂点的例子
比如下面一段代码:
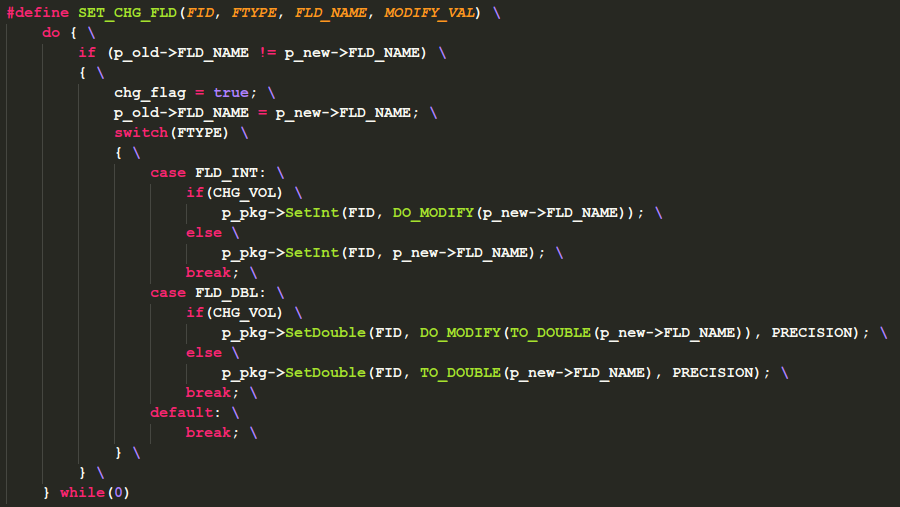
在阅读的时候就比较困难,像chg_flag、p_old、p_new、p_pkg等都要与具体的宏展开处的代码相关联,程序员需要用人脑将不同的代码段拼接起来,耗费脑力不说,还容易出错。
这段代码整体看起来还算清晰,对于一些一些有嵌套的宏定义代码段来讲,人脑拼接的时候会更困难,基本上代码跑通后就没人敢动了。所以为了少挨骂,还是不要写这么变态的代码了。
3.宏定义代码段的好处
宏定义也不是一无是处,如果自身的能力足够驾驭宏定义可能带来的坑,并且严格控制宏定义的使用场景以及代码规模的话,还是能带来运行效率和可读性的双重提升的。
说提高运行效率,其实是使用宏定义代替函数,可以避免调用函数时保存和恢复现场的开销。这一点在C语言时代是比较重要的,但是在C++时代,其效率提升的功能可由内联函数代替,可读性大大提高,而性能又基本无损失。
说提高可读性,其实是把一些简单到没必要写成函数的功能用宏定义代替了,以减少代码长度。比如下面这段代码:

但是像这种功能在现代C++中有更好的解决方法,那就是lambda表达式,这一点我们稍后讨论。
宏定义因其威力强大,可以突破语言的语法限制,用的好了确实能够达到出神入化的效果,但是需要相当的功力才行。据我所知,在开源领域还是有不少这种例子的。
比如linux内核中对list数据结构的操作就使用了大量的宏定义代码段(链接在此):
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_next_entry(pos, member))
/**
* list_for_each_entry_reverse - iterate backwards over list of given type.
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_last_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_prev_entry(pos, member))比如谷歌的gtest单元测试框架也使用了大量的宏定义,使得最终用户可以用很简洁的形式编写单元测试代码(链接在此):
#define EXPECT_TRUE(condition) \
GTEST_TEST_BOOLEAN_(condition, #condition, false, true, \
GTEST_NONFATAL_FAILURE_)
#define EXPECT_FALSE(condition) \
GTEST_TEST_BOOLEAN_(!(condition), #condition, true, false, \
GTEST_NONFATAL_FAILURE_)
#define ASSERT_TRUE(condition) \
GTEST_TEST_BOOLEAN_(condition, #condition, false, true, \
GTEST_FATAL_FAILURE_)
#define ASSERT_FALSE(condition) \
GTEST_TEST_BOOLEAN_(!(condition), #condition, true, false, \
GTEST_FATAL_FAILURE_)4.lambda表达式的核心特性
a) 核心特性快速回顾
C++11标准引入了lambda表达式特性,使得C++往现代语言又前进了一大步。
lambda表达式是一种可调用对象,在C语言时代,可调用对象只有函数和函数指针两种,C++11之前,重载了函数调用运算符的类对象也算是可调用对象的一种。
我们可以将lambda表达式理解为一个未命名的内联函数。与任何函数类似,一个lambda表达式具有一个返回类型、一个参数列表和一个函数体:
[capture list] (parameter list) -> return type { function body }
其中,捕获列表(capture list)是一个lambda表达式所在函数中定义的局部变量的列表。返回类型、参数列表和函数体都与普通函数无异。
如无必要,lambda表达式可以省略参数列表和返回类型不写,但捕获列表和函数体必须包含:
auto lambda_fucn = [] { return 2*3; }b) lambda表达式怎么用
lambda表达式定义在函数内,捕获的也是函数的局部变量,这一特性决定了lambda表达式非常适合封装那些函数体内较为繁琐的、重复出现的代码段。
lambda表达式自动捕获局部变量的特性,使得不用编写长长的参数列表即可使用一些变量,代码会因此变得简洁清晰,这一点是函数比不了的。
lambda表达式并不是来替代函数的,他其实是函数的一种补充,一些较为简单的,重复出现的,局部性的逻辑,可以使用lambda表达式实现,但较为复杂的,需要在较大范围内重用的逻辑,还得用函数实现。
5.使用样例
在实际的软件开发过程中,我们使用宏定义代码段,往往是用函数实现不了,或者不够经济。
宏定义突破语法限制对源代码进行文本替换的功能,别说函数,就是lambda表达式也替代不了,因此这部分功能该用还得用(但是除非非常有必要,尽量不要用)。
但是对于另一种情况,即用函数实现不够经济的情况,用lambda表达式往往能完美解决。
下面举几个例子:
a)函数比参数列表还长
比如像下面这段代码:
//compile with : g++ -o lambda_test_4 lambda_test_4.cpp -std=c++11
#include <stdio.h>
struct counter_t
{
int val;
};
int sum_counter(counter_t &a, counter_t &b, counter_t &c, int multply_d)
{
return (a.val + b.val + c.val) * multply_d;
}
int main()
{
counter_t a, b, c;
a.val = b.val = c.val = 1;
printf("sum = %d\n", sum_counter(a , b, c, 2));
auto lambda_sum_cnter = [&a, &b, &c](int multply_d)->int
{
return (a.val + b.val + c.val) * multply_d;
};
printf("sum = %d\n", lambda_sum_cnter(2));
return 0;
}像上述这种极其简单的逻辑,如果用函数写起来,参数列表比功能逻辑还长,用函数写显然不太经济。
而利用lambda表达式自动捕获局部变量的功能,我们让他自动捕获a、b、c三个变量,这样我们只需要传递一个参数multiply_d即可,看起来简洁了很多。
b) 局部性的重复逻辑
看下面这个例子:
//compile with : g++ -o lambda_test_5 lambda_test_5.cpp -std=c++11
#include <stdio.h>
#define FID_A 15
#define FID_B 6
#define FID_C 88
#define FID_D 23
#define FID_E 121
struct buffer_t
{
int val_vec[5];
};
void copy_buf(buffer_t &buf_x, buffer_t &buf_y)
{
if(buf_x.val_vec[0] != buf_y.val_vec[0])
{
//p_pkg->SetVal(buf_y.val_vec[0], FID_A);
buf_x.val_vec[0] = buf_y.val_vec[0];
}
if(buf_x.val_vec[1] != buf_y.val_vec[1])
{
//p_pkg->SetVal(buf_y.val_vec[1], FID_B);
buf_x.val_vec[1] = buf_y.val_vec[1];
}
if(buf_x.val_vec[2] != buf_y.val_vec[2])
{
//p_pkg->SetVal(buf_y.val_vec[2], FID_C);
buf_x.val_vec[2] = buf_y.val_vec[2];
}
if(buf_x.val_vec[3] != buf_y.val_vec[3])
{
//p_pkg->SetVal(buf_y.val_vec[3], FID_D);
buf_x.val_vec[3] = buf_y.val_vec[3];
}
if(buf_x.val_vec[4] != buf_y.val_vec[4])
{
//p_pkg->SetVal(buf_y.val_vec[4], FID_E);
buf_x.val_vec[4] = buf_y.val_vec[4];
}
}
void copy_buf_by_lambda(buffer_t &buf_x, buffer_t &buf_y)
{
auto lambda_cpy_buf = [&buf_x, &buf_y](int idx, int fid)
{
if(buf_x.val_vec[idx] != buf_y.val_vec[idx])
{
//p_pkg->SetVal(buf_y.val_vec[idx], fid);
buf_x.val_vec[idx] = buf_y.val_vec[idx];
}
};
lambda_cpy_buf(0, FID_A);
lambda_cpy_buf(1, FID_B);
lambda_cpy_buf(2, FID_C);
lambda_cpy_buf(3, FID_D);
lambda_cpy_buf(4, FID_E);
}
int main()
{
buffer_t buf_x, buf_y;
//copy_buf(buf_x, buf_y);
copy_buf_by_lambda(buf_x, buf_y);
return 0;
}我们的函数需要做一件事情,即检查buf_y的五个字段相对于buf_x是否有变化,如果有变化,把变化的字段填写到数据包中发出去。
我们提供了两个版本的实现,一个是用普通函数(注意五个FID是没有规律的,因此不能用循环),里面包含了大量的重复判断,但是又不能用循环实现。一个是用lambda表达式,捕获函数内的buf_x和buf_y变量,缩减了参数列表,同时又消除了重复部分,看起来非常简洁。
这个场景的关键是,局部和重复。如果逻辑具有全局性,那么尽量用函数;如果逻辑不具备重复性,那么还不如将大函数拆解成小函数,用lambda表达式反而有点得不偿失。
c) 高级用法:拓展作用域
在上面的文本中,我们多次用加粗的黑体字提醒您,lambda函数是局部的,只能捕获函数的局部变量。到那时其实我们可以利用一个小技巧,实现将lambda表达式的作用域拓展到函数外面。
我们将上面的例子稍加改造,如下:
//compile with : g++ -o lambda_test_6 lambda_test_6.cpp -std=c++11
#include <stdio.h>
#include <functional>
#define FID_A 15
#define FID_B 6
#define FID_C 88
#define FID_D 23
#define FID_E 121
struct buffer_t
{
int val_vec[5];
};
typedef std::function<void(int idx, int fid)> copy_func_t;
void copy_levels(copy_func_t cp_func)
{
cp_func(0, FID_A);
cp_func(1, FID_B);
cp_func(2, FID_C);
cp_func(3, FID_D);
cp_func(4, FID_E);
}
void copy_buf_by_lambda(buffer_t &buf_x, buffer_t &buf_y)
{
auto lambda_cpy_buf = [&buf_x, &buf_y](int idx, int fid)
{
if(buf_x.val_vec[idx] != buf_y.val_vec[idx])
{
//p_pkg->SetVal(buf_y.val_vec[idx], fid);
buf_x.val_vec[idx] = buf_y.val_vec[idx];
}
};
copy_levels(lambda_cpy_buf);
}
int main()
{
buffer_t buf_x, buf_y;
//copy_buf(buf_x, buf_y);
copy_buf_by_lambda(buf_x, buf_y);
return 0;
}要点如下:
- 我们用std::function定义了一个与lambda表达式参数列表相同的function类型(注意这里没有标明捕获的两个变量)
- 我们再定义一个函数,参数是上面定义的funciton类型,内部直接调用参数中的function(注意这个函数中并没有看到lambda表达式捕获的两个变量)
- 在原先的函数中,我们只定义lambda表达式,把定义的结果传递给另外的函数去调用
在上面的例子中,lambda捕获的变量在定义lambda表达式的函数中定义,但实际的使用确是在另外的函数中。相当于拓展了lambda表达式的作用范围。
这样有什么好处呢?
利用这个特性,我们可以把逻辑的实现集中起来,并且将逻辑的实现与调用分开。
对于一些较为通用的操作,我们可以定义一个入口函数,把实现以lambda表达式的形式集中写在入口函数中,这样方便将来维护;相关变量则统一传给入口函数,由lambda表达式捕获,这样入口函数调用下级函数的时候就不用写长长的参数列表了;最后入口函数将这些lambda表达式通过参数的形式传递给下级函数,由他们进行逻辑的调用。
6.并非万能
lambda表达式并非万能的,至少在以下两点上,lambda表达式尚不能取代宏定义代码段。
a) 不支持泛型
在前面的例子中,我们定的场景比较理想,buffer_t的所有的参数都是int类型的。而如果实际的开发工作中,重复代码存在,但参数不同,那我们就需要为每套参数都写一套lambda表达式,虽然他们的函数体一模一样。
这种情况下,lambda表达式消除重复代码的功能就大大削弱了。
好在C++20标准中预计加入泛型支持,让我们期待吧~~
而宏定义则完全不受限制,因为对宏定义来讲,就没有类型可言,何来泛型之说:
#define COPY_FIELD(OLD_VAL, NEW_VAL, FID) \
if(OLD_VAL != NEW_VAL) \
{ \
p_pkg->SetVal(NEW_VAL, FID); \
OLD_VAL = NEW_VAL; \
}比如上面这段代码就可以适配N多种类型,消除重复代码。
b) 不能突破语言语法限制
举一个简单的场景,假设我们要操作的是两个结构体的同名参数,用宏定义就可以简单的写成下面这种形式,很简洁:
#define COPY_FIELD(FLD_NAME, FID) \
if(old_buf.FLD_NAME != new_buf.FLD_NAME) \
{ \
p_pkg->SetVal(new_buf.FLD_NAME, FID); \
old_buf.FLD_NAME = new_buf.FLD_NAME; \
}
//调用
COPY_FIELD(fld_a, FID_A);因为宏定义是简单的文本替换,在你传入字段名称的时候,他会把下面的“对象名.字段名”补全,形成一段完整的代码。而lambda表达式就不行,必须直接完整的写出“对象名.字段名”,示例代码如下:
auto lambda_cpy_fld = [](int &old_val, int new_val, int fid)
{
if(old_val != new_val)
{
p_pkg->SetVal(new_val, fid);
old_val = new_val;
}
};
lambda_cpy_fld(buf_x.fld_a, buf_y.fld_a, FID_A);是不是看起来啰嗦多了?
7.参考资料
- C++ Primer中文版 第五版 10.3.2
2 thoughts on “使用lambda表达式替换宏定义代码段”
看这代码,我估计你是在上期技术工作的。方便的话 加个联系方式 哈哈
代码是之前预研用的老代码,具体工作抱歉不太方便透露,有问题可以随时留言,经常看网站