LINUX内核数据结构-HASHTABLE
1.前言
在读这篇文章之前,建议您先读一下上一篇介绍linux内核list实现的文章,链接在此。由于很多原理性的东西已经在上述文章中进行了阐释,因此这篇文章中不再重复描述。
Linux kernel 3.7 之后采用了由Sasha Levin设计的通用型 hashtable(代码在这里),为了方便大家理解hashtable的原理,我们并没有直接使用Sasha Levin的代码,而是把核心代码摘录了出来,这样看起来会更清晰。
本篇中的完整示例代码已经上传至我的github仓库,供您参考。
2.原理
大家都知道,hashtable的两个要点是散列函数和冲突处理方法(如果不知道建议先读下之前写的这篇文章)。linux内核的hashtable,要求用户自己实现散列函数,冲突处理方法为拉链法。
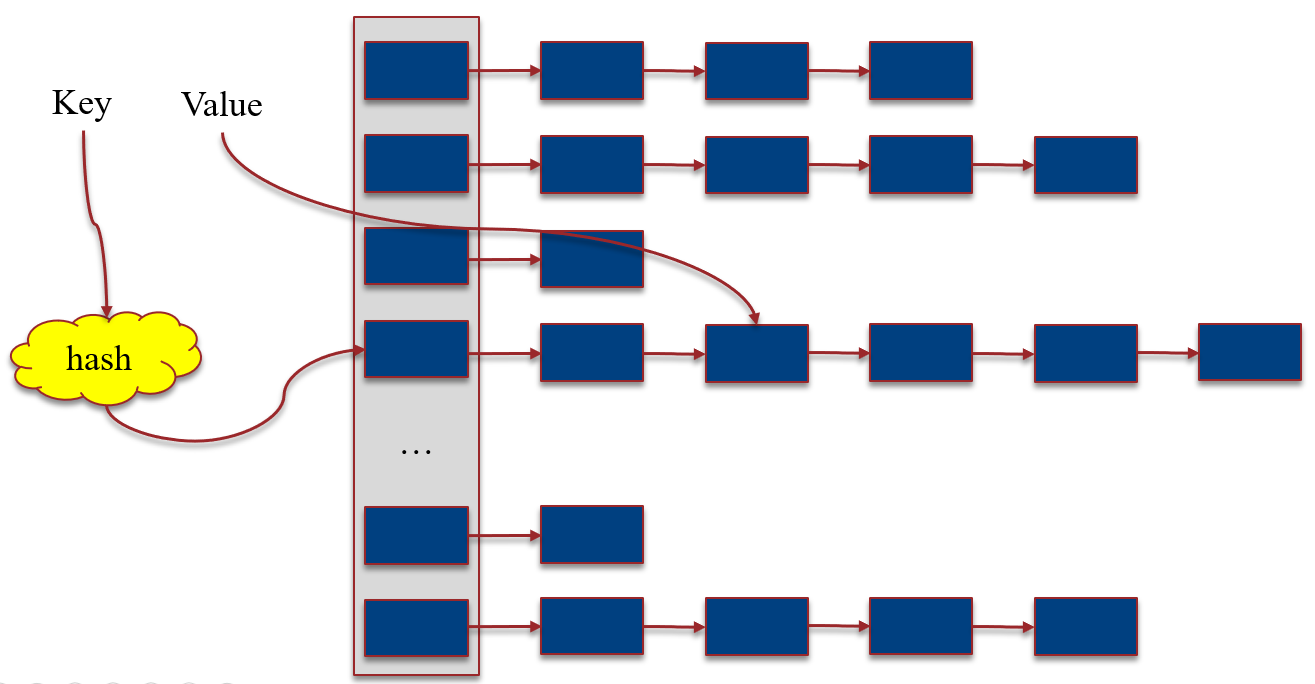
拉链法的链表,用的是hashlist(下面的篇幅会详细介绍);hashtable的桶,其实就是hashlist的数组;用户提供的散列函数,作用就是把hashtable的key映射为hashlist数组的下标。
3.hashlist
hashlist的代码与普通list的代码位于同一文件中,实现方式也是比较类似的。
定义头结点和普通节点:
// copy from kernel/include/linux/types.h
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
注意,普通链表是双向链表,因此不区分头结点和普通节点,他们使用同样的结构体,且同样只包含prev和next两个指向自己的指针。
hash链表则不同,他是单向链表,因此头结点中只包含一个指向第一个节点的指针。普通节点则包含两个字段,next字段指向下一个元素,pprev则是个指针的指针,指向前一个元素的next/first指针。之所以这样设计,是因为链表的第一个元素的prev与其他节点的prev的结构体不一样(一个是hlist_head,一个是hlist_node),但是他们的prev节点的next/first指针指向的结构体是一样的,因此可以统一用一个指向hlist_node的指针的指针来保存。
链表的初始化过程如下,其实就是把指针置空而已:
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}增加链表节点的函数如下:
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
该函数是从头部插入,具体操作也很简单,主要提醒一点,即pprev指针是指向前一个节点的next/first指针。
遍历过程如下:
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)
#define hlist_entry_safe(ptr, type, member) \
({ typeof(ptr) ____ptr = (ptr); \
____ptr ? hlist_entry(____ptr, type, member) : NULL; \
})
#define hlist_for_each_entry(pos, head, member) \
for (pos = hlist_entry_safe((head)->first, typeof(*(pos)), member);\
pos; \
pos = hlist_entry_safe((pos)->member.next, typeof(*(pos)), member))
hlist_for_each_entry中多次调用了hlist_entry_safe宏定义,hlist_entry_safe则是在普通的hlist_entry上包了一层,对指针做了下判空。
for循环本体也比较好理解,起始节点是head节点的first指针,即链表的第一个节点,终止条件是指针非空,取下一个节点时,取用户自定义结构体内嵌的hlist节点的next指针即可。
4.初始化
首先得定义一个结构体,嵌入hlist_node结构体:
struct order_node_t
{
long hkey;
long order_ref;
struct hlist_node hnode;
};在这里,我们以保存订单结构为例。其中hkey字段保存的是该订单结构体的hashkey,在发生散列冲突时,利用hashkey字段是否相同可判断我们是否找到了想要的订单结构体
然后,我们需要定义hash函数:
#define HTBL_BKT_CNT 7
static inline int hash_func(int order_no)
{
return order_no % HTBL_BKT_CNT;
}这里为了方便理解,我们直接用订单号与hashtable桶的个数(本例中为8)取模,这样就能根据订单号,把订单结构体映射到其中一个桶(即hashlist)中。
然后我们定义并初始化hashtable:
//hashtable buckets
struct hlist_head h_ord_tbl[HTBL_BKT_CNT];
for (i = 0 ; i < HTBL_BKT_CNT ; i++)
{
INIT_HLIST_HEAD(&h_ord_tbl[i]);
}定义hashtable其实就是定义一个hashlist的数组,每个hashlist都是hashtable的一个桶。初始化也很简单,就是对每个hashlist调用INIT_HLIST_HEAD,把头结点的first指针置空。
5.增加元素
增加元素的示例代码如下:
//add elements to table
for (ord_no = 0 ; ord_no < ORDER_CNT ; ord_no++)
{
p_ord = (struct order_node_t *)malloc(sizeof(struct order_node_t));
p_ord->hkey = ord_no;
p_ord->order_ref = ord_no;
INIT_HLIST_NODE(&p_ord->hnode);
bkt_idx = hash_func(ord_no);
hlist_add_head(&p_ord->hnode, &h_ord_tbl[bkt_idx]);
}- 新建一个用户自定义的结构体
- 初始化他的hashlist节点字段
- 调用自定义的hash函数,将订单号映射为hashtable桶数组的一个下标,从而找到了对应的hashlist
- 然后将自己插入该hashlist即可
6.查找
查找数据的示例代码如下:
//search from hashtable
for (ord_no = 0 ; ord_no < ORDER_CNT ; ord_no++)
{
bkt_idx = hash_func(ord_no);
hlist_for_each_entry(p_ord, &h_ord_tbl[bkt_idx], hnode)
{
if (p_ord->hkey == ord_no)
printf("%ld, %ld\n", ord_no, p_ord->order_ref);
}
}- 仍然是先调用自定义的hash函数,将订单号映射为hashtable桶数组的一个下标,从而找到了对应的hashlist
- 然后遍历该hashlist,找到与要查找的元素hashkey相同的那个
注意,如果hash桶中的hashlist的长度大于1,那么就是发生了冲突,发生冲突时要对hashlist进行遍历,因此冲突过多是会影响hashtable的性能的,用户可通过合理的设计hash函数来降低冲突概率,进而提高hashtable的性能。
7.遍历
hashtable的遍历代码如下:
//hashtable foreach
for (bkt_idx = 0 ; bkt_idx < HTBL_BKT_CNT ; bkt_idx++)
{
hlist_for_each_entry(p_ord, &h_ord_tbl[bkt_idx], hnode)
printf("%ld\n", p_ord->order_ref);
}其实就是遍历桶,然后遍历桶中(hashlist)的元素,运行效果如下:

散列函数的存在,会导致hashtable中的元素大致均匀且分散地存储在hashtable的每个桶(hashlist)中,因此按照上述过程进行遍历时,你会发现数据似乎是无序,这也就是stl的hash容器为什么都叫unordered_xxx的原因。