大端序、小端序、网络字节序
1.大端序、小端序
资料来源:《UNIX网络编程 卷1》 3.4 字节排序函数
对于一个16位的整数,他由两个字节组成。内存中存储这两个字节有两种方法:一种是将低序字节存储在起始地址,称为小端(little-endian)字节序;另一种方法是将高序字节存储在起始地址,称为大端(big-endian)字节序。
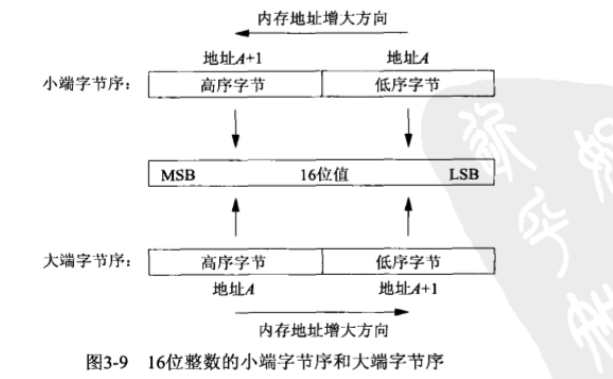
*术语大端和小端表示多字节整数的哪一端(小端和大端)存储在该值的起始地址。
*我们把某个给定系统所用的字节序称为主机字节序。
*当今有不少系统能够在系统复位时(例如MIPS 2000),或者在系统运行之时(例如Intel i860),在大小端字节序之间切换
2.实验
通过下面的程序可以测试你的主机是什么字节序。
/*************************************************************************
> File Name: byte_test.c
> Author: Jack Wong
> Mail: pandawkx@163.com
> Created Time: Fri 30 Oct 2015 08:36:58 AM CST
************************************************************************/
#include <stdio.h>
int main()
{
union{
short s;
char c[sizeof(short)];
}un;
un.s = 0x0102;
if(sizeof(short) == 2)
{
if(un.c[0] == 1 && un.c[1] == 2)
printf("big-endian\n");
else if(un.c[0] == 2 && un.c[1] == 1)
printf("little-endian\n");
else
printf("unknown\n");
}
else
printf("sizeof(short) = %d\n",sizeof(short));
return 0;
}1.联想笔记本(CentOS6.5 X86_64)执行结果:

平台:

2.Windows(Win7)执行结果:

平台:
3.Linux(Redhat6.5)执行结果:

平台:

4.HPUX执行结果:

平台:

5.MAC OS X执行结果:

平台:

*从以上设备中,基于X86平台的是小端序,基于ia64平台的是大端序。
3.网络字节序
网络协议必须指定一个网络字节序,作为网络编程人员和我们必需清楚不同字节序之间的差异。举例来说,在每个TCP分节中都有16位的端口号和32位的IPv4地址。发送协议栈和接收协议栈必需就这些多字节字段各个字节的传送顺序达成一致。网际协议使用大端字节序来传送这些多字节整数。
*注意这里的字节序约定是协议栈之间约定的。应用层传送的是字节流,你在一台机器上怎么传送过去的,在另一台机器上就会怎么接收到。字节顺序不变。在一般应用下,我们根本不用关心字节序的问题。
下面考虑一种需要考虑字节序的特殊情况:
假设主机A是小端序,主机B是大端序,两个平台上整数都是4个字节。我们在主机A上直接把这四个字节的数据传送到主机B上,主机B把这四个字节的数据当成一个整数来用,这会导致什么后果?
主机A传送的数据:00000000 00000000 00000000 00000001
主机B接收到的数据:00000000 00000000 00000000 00000001
主机A把这四个字节当成一个整数:这个整数为00000000 00000000 00000000 00000001 == 1
主机B把这四个字节当成一个整数:这个整数位00000001 00000000 00000000 00000000 == 2^24 = 16777216测试结果:

*字节序问题通常在通讯双方使用二进制协议(使用文本协议的时候无需考虑)的时候才需要考虑。如果两台机器的主机序不同,那么就要考虑统一字节序。
4.字节序转换函数
#include <netinet/in.h>
uint16_t htons(uint16_t host16bitvalue);
uint32_t htonl(uint32_t host32bitvalue); //均返回网络字节序
uint16_t ntohs(uint16_t net16bitvalue);
uint32_t ntohl(uint32_t net32bitvalue); //均返回主机字节序
#include <endian.h>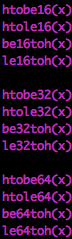
be = big endian
le = little endian
其中h代表host,n代表network,s代表short,l代表long。