libevent事件循环的几种方式
1.最简单的方式
最简单的使用方式是调用event_base_dispatch,声明如下:

注册完事件后,调用此函数,当前线程即进入此函数中执行事件循环。除非用户主动调用event_base_loopbreak或event_base_loopexit结束事件循环,或事件循环中没有任何注册事件为止。
采用这种方式时,一般会启动一个单独的线程,专门运行事件循环,处理数据的收发事宜。而数据在业务层面上的处理,一般会被委托出去,使用另外的线程处理。
如果你的event_loop并不繁忙,比如只处理几个TCP连接,这时候用单独的线程运行event_loop就不太经济了,因此你可能想让自己的线程在运行event_loop之余顺带处理一些其他事情。这时候,event_base_dispatch的行为方式就不能满足要求了,你需要高级的玩法。
2.高级玩法
我们看event_base_dispatch这个函数的实现:
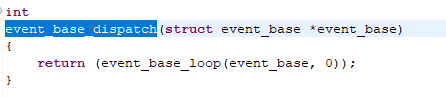
他在底层调用的是event_base_loop这个函数。该函数声明如下:
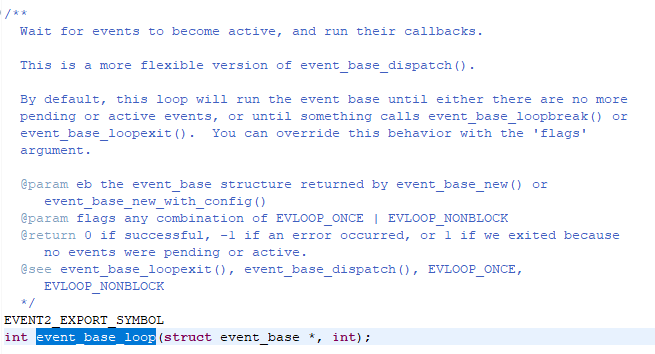
这个函数有个flags参数,我们调用event_base_dispatch的话, 其实是调用了flags参数为0的event_base_loop函数。
这个flags有如下几个选项:

为了说明这几个选项的含义,我们假设如下场景:
- 我们在event_loop中为一个TCP连接注册了可读信号
- 程序所在的主机从网络上收到了发往该TCP连接的120字节的数据
- 这120字节的数据,程序逻辑上需要分两次收完(即调用两次recv函数)
- 第一次收40字节
- 第二次收80字节
- 因此,程序需要两次可读回调才能收完这120字节的数据
那么问题来了,要收到两次回调的话,需要调用几次event_loop函数呢?
a) flags指定为0
即相当于前面的简单用法。这种情况下event_loop会阻塞,因此只需要调用一次。但问题是即使这120字节已经收完了,event_loop也不会退出,这不是我们想要的效果。
b) flags指定为EVLOOP_ONCE
该flag的含义是,每次循环只处理优先级最高的一个事件。
在上面的例子中,我们需要运行两次event_loop,第一次响应可读事件收40字节的数据,第二次响应可读事件收剩余的80字节的数据。
虽然这次event_loop不会阻塞了,但是event_loop的效率又太低了,也不是我们想要的效果。
c) flags指定为EVLOOP_NONBLOCK
该flags的含义是,每次event_loop会循环处理完所有事件,直到没有新的待处理事件为止。
在上面的例子中,event_loop会在内部运行两轮事件循环,第一轮响应可读事件收取40字节的数据;第二轮收取剩余80字节的数据。两轮事件循环结束后,event_loop退出。
这正是我们想要的效果,即不会阻塞当前线程,event_loop的效率又高。
但是这种行为有一个问题,即如果连接很繁忙,一直有数据从网络上过来,那么event_loop会一直无法退出。因此只适用于事件循环不太繁忙的场景。
d) flags指定为EVLOOP_NO_EXIT_ON_EMPTY
该flags比event_base_dispatch的行为还要极端。event_base_dispatch在没有任何注册事件的时候会退出,而指定了该标记的event_base_loop不会。
两者相同的一点是,用户主动调用event_base_loopbreak或event_base_loopexit是可以结束事件循环的。
3.总结
每种玩法适用于不同的场景,libevent的设计者都提前想到了,大家可以根据不同的应用场景灵活选用。
如果你听不懂我上面说的什么,证明你对网络编程还不熟悉,尤其是反应器模式不太熟悉,这里推荐一本书《Linux多线程服务端编程-使用muduo网络库》。我就是从这本书开始入门网络编程的。
另外多说一点,我本人在开发过程中深度使用过两个网络库,一个是ACE,一个是libevent,还基于libevent封装了一个功能完备、使用起来更简单的网络库,还做过几个工业级的以网络通信为核心功能的系统,因此在网络编程方面还是有发言权的。
听我一句劝,千万别碰ACE。要用好这个库,需要相当的功力才行。对功力的要求不亚于能重新写一个简单的网络库。
另外一个原因是,这个库至今还有一个我发现的未修复的bug,我们在实际项目中采用继承替换实现的方式解决了这个问题。